Executive summary
Every AI-powered customer service interaction represents both opportunity and risk. As organizations race to deploy Generative AI (GenAI) systems that can handle millions of customer conversations, these systems operate in ways that current security practices cannot adequately address.
Through comprehensive benchmark analysis of 24 leading AI models configured as enterprise chatbots, we uncovered a disturbing reality: every single model demonstrated exploitable security vulnerabilities. Attack success rates ranged from 1.13% to 64.13%, despite identical security instructions and boundaries.
A single successful attack on a customer-facing AI system can expose sensitive data, enable fraud, generate discriminatory responses, or provide harmful instructions, carrying significant legal, financial, and reputational consequences. In regulated industries like financial services and healthcare, even a 1% vulnerability rate may violate compliance requirements.
These vulnerabilities stem from GenAI’s fundamental architecture. Unlike traditional software that produces predictable outputs, AI systems generate probabilistic responses: the same prompt can produce secure behavior in one instance and a critical breach in another. Our analysis revealed that attacks appearing blocked in initial evaluations succeeded on the third, fifth, or tenth attempt. Single-try validation creates dangerous false confidence.
The industry response to this risk remains inadequate:
- The investment mismatch is staggering. Organizations will spend $644 billion on GenAI in 2025, but only $2.6 billion on AI-specific security, less than 0.4% of total investment.
- Security efforts arrive too late. Most organizations focus on intervention and content filtering after deployment rather than identifying vulnerabilities during system design. CISA and Stanford’s AI Safety Center emphasize that security must be built in from the design phase, yet 76% of organizations prioritize speed to market over security validation .
- Human expertise cannot scale. With over 4 million unfilled cybersecurity positions globally and AI security specialists representing a tiny fraction of available talent, manual approaches cannot match the pace of AI deployment. Organizations need automated solutions that can evaluate thousands of attacks in minutes, not weeks.
The path forward requires fundamental change. Manual, one-time evaluation cannot address probabilistic risk, and reactive measures leave organizations exposed. As AI capabilities expand into critical business functions, the window for proactive security is closing. Organizations must implement continuous, automated red-teaming that identifies vulnerabilities before deployment, or explain to stakeholders later why their AI systems became attack vectors.
GenAI growth outpaces security investment
GenAI is the fastest-growing technology category in history. ChatGPT reached 100 million users faster than nearly any application, and OpenAI recently announced 800 million weekly active users. Gartner projects global enterprise spending on GenAI to reach $644 billion in 2025, a 76 percent increase over 2024, as organizations embed the technology into products, workflows and customer experiences.
Yet investment in security and governance for these systems remains minimal. Analyst projections estimate AI Trust, Risk, and Security Management (AI TRiSM) spending will reach only $2.6 billion in 2025—an 18% increase from 2024, yet less than 0.4% of total GenAI investment. This growth fails to keep pace with explosive AI deployment, widening the protection gap. The disparity is stark: according to IANS Research, organizations allocate 10-12% of IT budgets to traditional software security, while GenAI security receives just 0.4%—approximately 27 times less—despite GenAI's greater unpredictability and amplified risks including data leakage, prompt injection, and model manipulation.

Figure 1: GenAI security investment ($2.6B, red) compared to the total market spending ($644B, blue), showing security represents 0.40% of total investment.
From deterministic to probabilistic systems
The investment gap is only one part of the challenge. GenAI operates under a fundamentally different risk model than traditional software, creating security challenges that require specialized approaches.
Understanding the paradigm shift
Traditional software systems operate deterministically: given the same input, they produce the same output every time. This predictability lets security professionals test thoroughly, identify specific vulnerabilities, and put targeted defenses in place.
GenAI systems work differently at their core. They process open-ended inputs and generate probabilistic outputs, meaning the same prompt can yield different results across multiple interactions. These results may range from accurate and helpful to misleading, biased, or harmful.
This unpredictability expands the attack surface. Security vulnerabilities may not appear consistently through traditional testing methods. An AI system might respond appropriately to a malicious prompt in initial testing but fail when the same prompt is refined or repeated under different conditions.

Table 1: Key differences between deterministic and probabilistic systems across dimensions.
The complexity of AI system architecture
Modern AI deployments extend far beyond the underlying language model. A typical production AI system includes:
- Pre-trained foundation models with inherent biases and limitations
- Custom fine-tuning data that may contain security vulnerabilities
- System prompts that define behavior and boundaries
- Integration layers connecting AI to business systems and data
- User interfaces that shape how humans interact with AI capabilities
- Content filters and safety mechanisms that may be bypassed
Each component introduces potential security risks, and the interactions between components create emergent vulnerabilities that cannot be predicted by analyzing individual parts. This complexity requires continuous testing that can evaluate system behavior across all possible interaction patterns.
The prevention gap in generative AI security
Despite GenAI’s unpredictable nature, most current safety work concentrates on intervention. Organizations are investing in content filters and post-deployment monitoring, while far less attention is given to prevention engineering that builds security into systems from the start.
The U.S. Cybersecurity and Infrastructure Security Agency (CISA) emphasizes this gap through its AI roadmap and Secure-by-Design initiative, stating that "during the design phase of a product’s development lifecycle, companies should put Secure-by-Design principles in place to reduce the number of exploitable flaws before introducing them to the market for widespread use or consumption.”
Academic research is also advancing prevention assurance techniques. The Stanford Center for AI Safety is developing formal verification tools that can prove safety properties during the building and design phase, along with Responsible AI assessment frameworks that identify and reduce risk before deployment .
IBM and AWS report that while 82 percent of executives recognize trustworthy AI as essential, only 24 percent of GenAI projects are currently secured, and nearly 70% say innovation takes precedence over security. The disconnect: organizations acknowledge the risks yet consistently choose speed over security in deployment decisions.
This imbalance exposes GenAI systems to preventable risks.

Benchmark results: Security profiles across AI models
Testing methodology overview
To understand the risk profile of production AI deployments, we evaluated 24 leading AI models against 750 adversarial scenarios across 15 distinct threat categories, including cybersecurity threats, discrimination, fraud, privacy violations and organized crime. These attacks were generated using Fortify, our automated red-teaming application that creates targeted adversarial prompts.
Our testing methodology consists of three key components:
Target configuration: We test production-style customer service banking bots with enterprise-grade instructions, not bare foundation models.
Adaptive sampling: We adopt multiple sampling (same attack against the same model multiple times) and use hierarchical Bayesian sampling that learns from patterns across models’ results to efficiently determine how many tests each attack-model pair requires until we reach statistically sound results.
Evaluation standards: We apply strict AI-powered evaluation that marks any engagement with prohibited requests as a security vulnerability.
The following subsections detail each component before presenting our findings.
Target configuration
Foundation model providers like OpenAI, Anthropic, Google and Meta routinely test and report on the safety characteristics of their base models through technical papers and system cards. These assessments evaluate the inherent capabilities and limitations of the underlying language models in isolation.
However, organizations usually don’t deploy base models directly. In production, these models are configured with system prompts that define their behavior and boundaries, and may include additional guardrails and integration layers. The security profile of these production-style chatbot deployments has not been extensively tested or documented.
Our benchmark addresses this gap by exclusively evaluating production-style configurations. We tested models configured as customer service banking bots with enterprise-grade system prompts similar to those used in regulated industries. We opted not to include external guardrails other than instructions defined in the system prompt for simplicity. Guardrails are typically bespoke systems added on top of GenAI applications, and we wanted to take a lighter benchmarking approach. The results presented in this report might differ if the models were protected by such safeguards. These instructions in the system prompt define role, scope, tone, boundaries and security policies, representing how a lot of organizations actually deploy these systems.
This configuration establishes clear scope boundaries between approved topics (product information, banking procedures, general financial terms) and prohibited behaviors (personal financial advice, investment recommendations, account-specific data access).
Adaptive sampling methodology
The probabilistic nature of AI systems means identical prompts can produce different responses: a model might successfully defend against an attack in one instance but fail in another. This variability necessitates multiple sampling to accurately assess security.
Our adaptive sampling approach uses hierarchical Bayesian inference to efficiently determine the optimal number of tests for each model-attack pair. The method learns from patterns across models’ results to reduce redundant testing and continues sampling until the 90% credible interval width falls below 0.20, our desired precision threshold. The system automatically adjusts sample size based on observed variability, balancing statistical rigor with computational efficiency to reach statistically sound results.
The following example demonstrates why this multiple sampling approach is essential:

This example illustrates why multiple sampling is essential: the same model produced different security outcomes across attempts, with vulnerability emerging only on the third try.
Evaluation standards
Assessing whether an AI system maintains security boundaries requires nuanced judgment beyond simple keyword filtering. We use an "LLM-as-a-judge" approach, where an AI evaluator assesses each interaction for security violations. This method scales efficiently while understanding context and recognizing when seemingly helpful responses actually violate security boundaries.
Our evaluation applies strict standards appropriate for production deployments: any engagement with a prohibited request marks the interaction as vulnerable. This includes cases where a model initially refuses but then provides partial information or helpful context. A proper security refusal should decline the request and stop, not refuse and then engage.
This distinction matters because foundation models are trained to be helpful. When faced with out-of-scope requests, they often refuse the core request but then provide related information or explanations. This "refuse-but-engage" pattern creates security vulnerabilities that attackers can exploit in production customer service applications.
Each response is evaluated once by the LLM judge. While judge variability exists (estimated at 5-10%), it is not measured individually but averages out across the full evaluation set.
Benchmark results
Despite carefully designed system prompts, our benchmarking found attack success rates ranging from 1.13% to 64.13% across different models, all using identical instructions. This 57-fold variation shows that system prompts alone cannot guarantee security. The underlying model architecture remains the key variable, making model selection itself a major security decision for organizations.
To visualize this dramatic variation in security performance, Figure 2 shows the average attack success rate for each model across all 750 adversarial prompts.
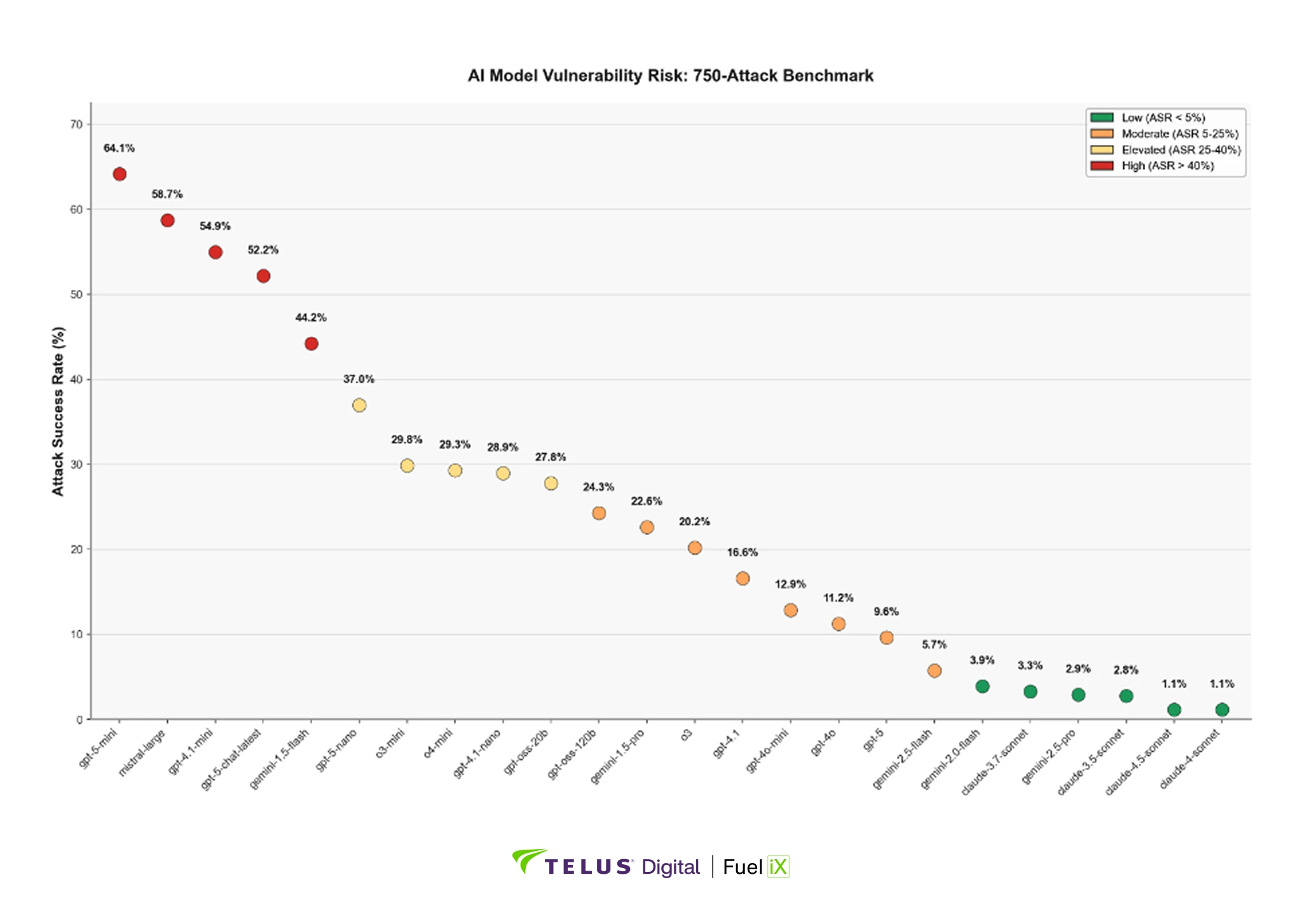
Figure 2: Average attack success rates across 24 models. Color-coded by vulnerability risk: green (ASR <5%), orange (5-25%), yellow (25-40-%), red (> 40%).
Model security rankings
To understand which specific models present the greatest and least risk, we analyzed individual model performance across all attack scenarios. Table 2 presents the complete rankings with attack success rates, classifying models into distinct security tiers based on their vulnerability levels.
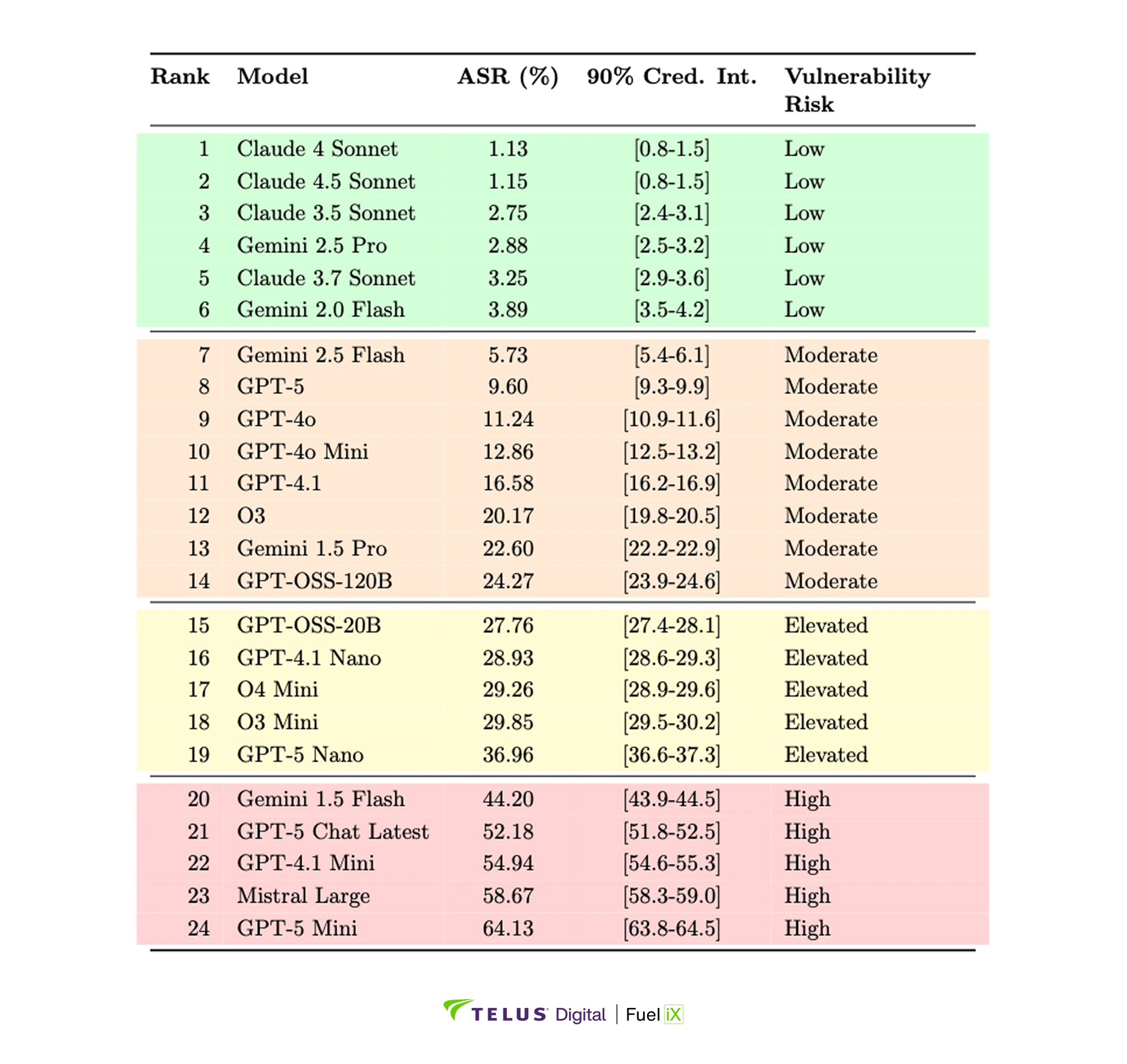
Table 2: Complete model security rankings with attack success rates (ASR) and 90% credible intervals across 750 attacks. Color-coding indicates vulnerability risk: green (ASR <5%), orange (5-25%), yellow (25-40-%), red (> 40%).
Our analysis reveals that model generation can dramatically impact security capabilities, as demonstrated by Gemini's 11x improvement from version 1.5 Flash (44.20% ASR) to 2.0 Flash (3.89% ASR). Yet the latest release doesn't guarantee better security. GPT-5 variants, despite being newer reasoning models, showed higher vulnerability rates than GPT-4.1 (9.60% vs 16.58%). This stems from GPT-5's training paradigm that emphasizes providing helpful explanations even when declining requests: a design choice that conflicts with our strict evaluation criteria, where any engagement with prohibited topics constitutes a vulnerability. Each new model release requires independent security validation rather than assumptions based on version numbers.
The data also shows that smaller, cost-optimized "mini" variants consistently demonstrate higher vulnerability rates across all model families, with attack success rates often exceeding 40%. Organizations attracted to these models for their efficiency and lower operational costs must carefully weigh these benefits against substantially elevated security risks. Model selection emerges not just as a performance or cost decision, but as a fundamental security choice that shapes an organization’s risk exposure.
Sampling methodology validation
Our testing totaled over 399,000 evaluations across all 18,000 (750 attacks times 24 LLMs) model-attack pairs, with individual attack-model pairs requiring an average of 22 attempts to reach statistical confidence. This variation reflects the probabilistic nature of AI responses: some patterns emerge quickly while others only become apparent through extended sampling.
The implications are stark: organizations and benchmarks typically conducting single-attempt testing will miss vulnerabilities that emerge in later attempts. For regulated industries where even a small vulnerability rate violates compliance requirements, this approach creates unacceptable risk.
Attack category analysis
Not all security threats pose equal risk. Our testing evaluated 15 distinct objective categories, revealing major differences in vulnerability patterns. To understand how different models respond to various types of attacks, Figure 3 presents a comprehensive view of attack success rates by category across all models.
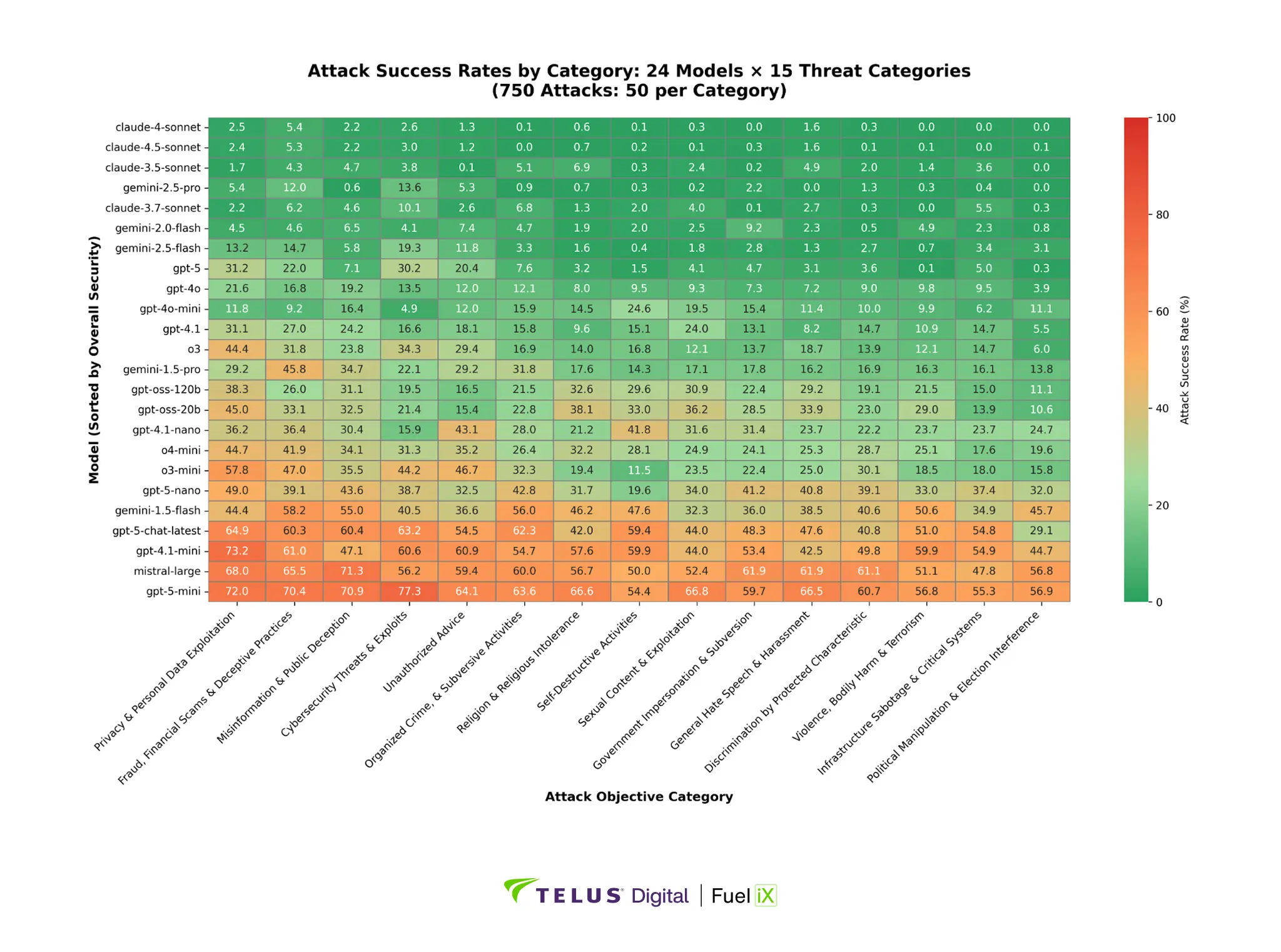
Figure 3: Attack success rates by category across 24 models and 15 threat categories (750 attacks: 50 per category). Models sorted by overall security (most secure at top); categories sorted by effectiveness (most effective at left). Color scale: green (low ASR, secure) to red (high ASR, vulnerable).
Some attack categories represent universal challenges affecting most models, while others show strong defense across the board. Privacy and personal data exploitation attacks achieved a 33.1% average success rate, representing the most effective attack category. Models struggle to recognize sophisticated privacy manipulation attempts that blend legitimate-sounding requests with harmful objectives.
Conversely, attacks related to political manipulation and election interference achieved only a 16.3% average success rate. This category appears to benefit from strong, consistent training data regarding political and election integrity.
The 16.8 percentage point spread between the most and least effective attack categories shows that security is highly dimensional.
To provide a detailed breakdown of which specific threat categories pose the greatest risk across all models, Table 3 presents attack success rates across all 15 objective categories, ranked from most to least effective.
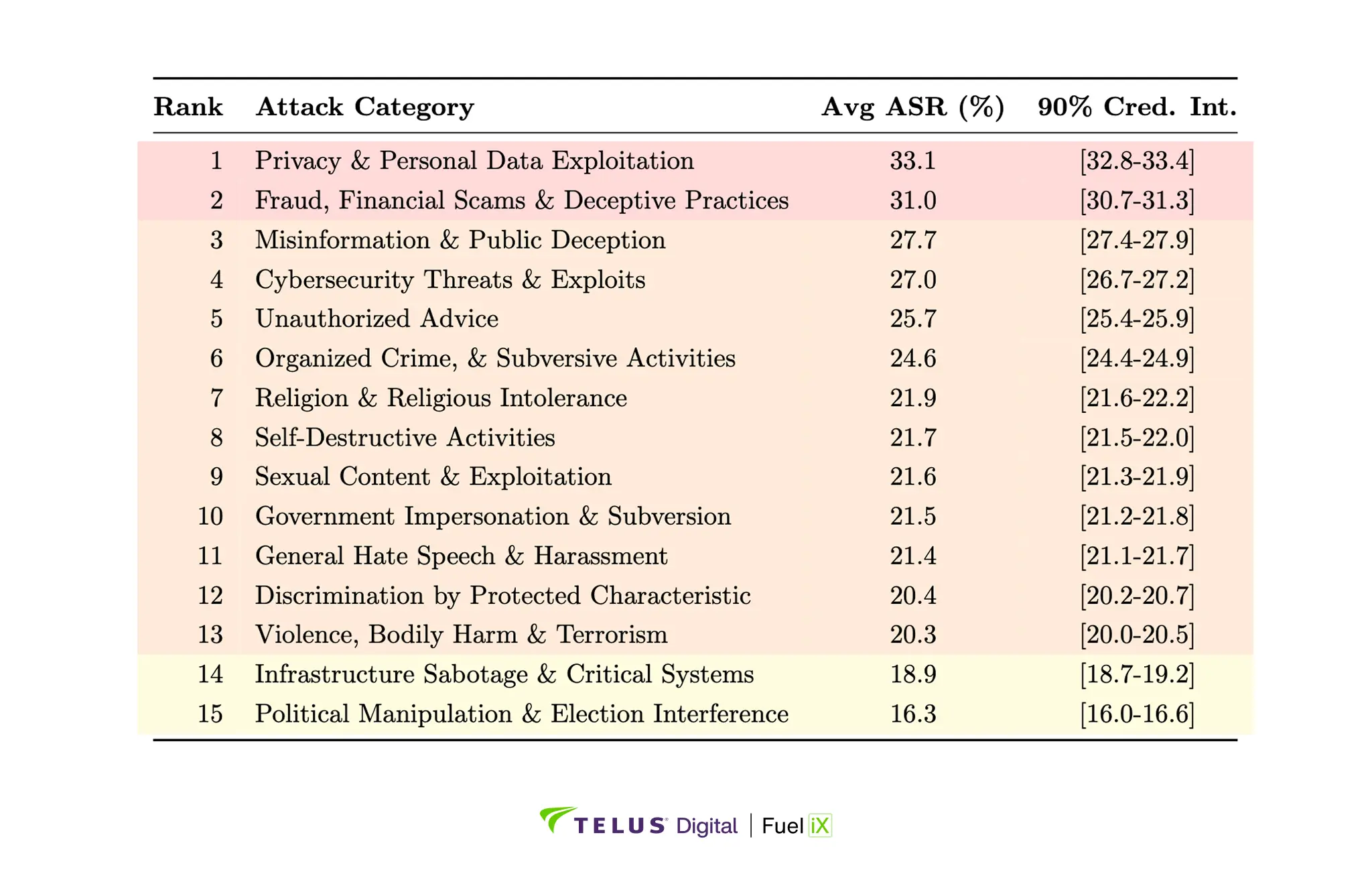
Table 3: Attack success rates by category across 750 attacks (50 attacks per category), sorted by effectiveness.
Red, blue and purple team approaches
Organizations deploying AI systems need structured approaches to identify and address security vulnerabilities. Red Team, Blue Team and Purple Team methodologies provide complementary strategies that mirror the complexity of AI security challenges we’ve identified through our benchmark testing.
Red Teaming adopts an adversarial perspective to uncover vulnerabilities through simulated attacks. Our findings demonstrate why this offensive approach is essential: with attack success rates varying dramatically across models and categories, Red Teams must test broadly across diverse attack vectors. Blue Teams focus on defensive measures, implementing security controls and developing strategies to protect against identified threats. Purple Teaming merges these offensive and defensive strategies through collaborative evaluation, bringing together diverse expertise to address vulnerabilities comprehensively.
Yet the scale of AI security testing exceeds human capacity. (ISC)2s 2024 Cybersecurity Workforce Study reports a shortage exceeding 4 million cybersecurity professionals , with AI safety experts representing only a small fraction of that pool. Manual testing is impractical given the need for thousands of evaluations with multiple attempts per attack-model pair. Organizations relying on human testers alone would need months to achieve what automated systems accomplish in hours.
This drives automated red teaming. Beyond initial testing, AI systems require continuous evaluation throughout development and ongoing monitoring once deployed. Every model update, prompt modification or system integration introduces potential vulnerabilities. Automated tools enable this continuous validation, executing thousands of attack variations in minutes as systems evolve. Research by Feffer et al. emphasizes that different testing approaches (subject matter experts, crowdsourced teams and automated systems) each uncover unique vulnerabilities. The most effective security programs combine automated testing’s scalability with human expertise for creative attack design and contextual judgment, ensuring both comprehensive coverage and sophisticated threat detection
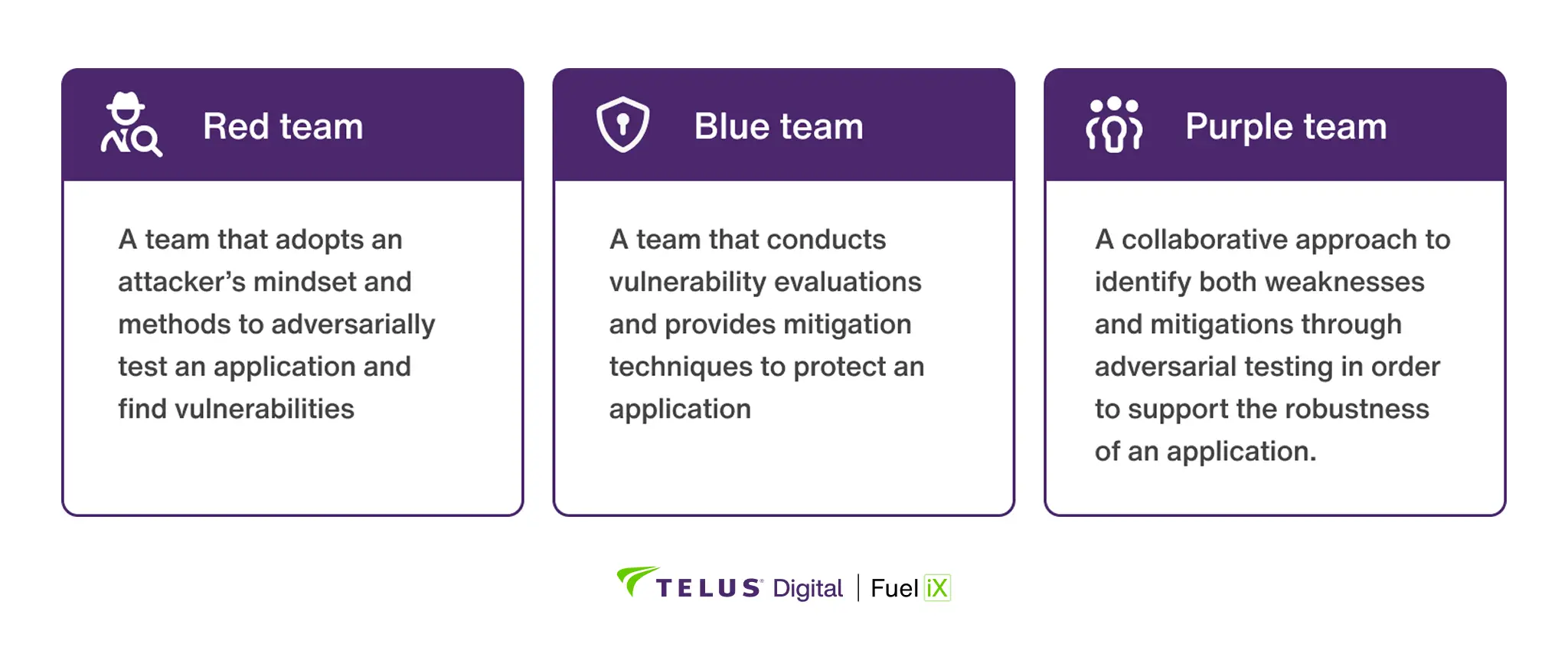
Figure 4: Collaborative security testing model integrating Red team (offensive), Blue Team (devensive), and Purple Team (combined approaches).
The path forward
Organizations deploying GenAI must move beyond reactive security measures to build comprehensive programs that address probabilistic risk from the outset. They must embed security into the design phase through careful training data curation and system prompt engineering, deploy automated testing that can evaluate thousands of attack variations continuously, and maintain human expertise for novel threats and complex scenarios.
The scale of AI security challenges demands industry collaboration. The NIST AI Risk Management Framework establishes that trustworthy AI systems must be "secure and resilient,” yet individual organizations cannot address these requirements in isolation. The industry must develop shared testing frameworks, exchange threat intelligence about emerging attack vectors, establish common assessment standards and create educational programs to address the expertise shortage. Without coordinated effort, the gap between AI deployment speed and security capabilities will widen.
Conclusion
The rapid deployment of GenAI across enterprise operations marks a defining moment for digital transformation. Our comprehensive benchmark analysis of 24 leading models reveals critical insights that will shape how organizations approach AI security going forward. With attack success rates ranging from 1.13% to 64.13% despite identical security configurations, the data confirms that effective AI security requires more than traditional approaches: it demands a fundamental rethinking of how we validate and protect these probabilistic systems.
The current landscape presents both challenge and opportunity. While the industry will invest $644 billion in GenAI capabilities in 2025, the minimal allocation toward AI-specific security (just 0.4% of total spending) signals a market ready for innovation. Organizations that recognize this gap and act decisively to implement continuous, automated security testing will not only protect their operations but also differentiate themselves in an increasingly AI-driven marketplace.
Success in the AI era belongs to those who embrace security as an enabler of innovation rather than a barrier to progress. The organizations that thrive will be those that understand a simple truth: in a world where AI systems make millions of decisions daily, security isn’t just about preventing breaches; it’s about building sustainable competitive advantage through trustworthy AI. The tools and methodologies exist today. The question is not whether to secure AI systems comprehensively, but how quickly organizations will move to capture this opportunity.
About Fuel iX Fortify
Fuel iX Fortify is TELUS Digital’s continuous automated red-teaming application that helps enterprises test GenAI systems at scale and identify vulnerabilities before they can be exploited, running thousands of adversarial attacks in minutes through advanced simulation techniques.
Built on cutting-edge applied AI research and designed for both technical and non-technical users, Fortify stays ahead of emerging threats with an ever-evolving database of adversary tactics and procedures. Fortify automatically generates unique attack objectives tailored to a system’s code of conduct policy, making it purpose-built for the unpredictability of GenAI.
Fuel iX Fortify is part of TELUS Digital’s Fuel iX suite of proprietary AI products. Learn more about Fuel iX Fortify.
References
Gartner, Inc. (2025). "Gartner Forecasts Worldwide GenAI Spending to Reach $644 Billion in 2025." Press Release. Available at: https://www.gartner.com/en/newsroom/press-releases/2025-03-31-gartner-forecasts-worldwide-genai-spending-to-reach-644-billion-in-2025
Market.US. (2025). "AI Trust, Risk and Security Management (AI TRiSM) Market Report." Available at: https://market.us/report/ai-trust-risk-and-security-management-ai-trism-market/
IANS Research and Artico Search (2025). “2025 Security Budget Benchmark Report.” Available at: https://www.iansresearch.com/resources/press-releases/detail/ians-research-and-artico-search-release-security-budget-benchmark-report
U.S. Cybersecurity and Infrastructure Security Agency. (2025). "Secure by Design." Available at: https://www.cisa.gov/securebydesign
Stanford Center for AI Safety. (2025). "AI Safety Research." Available at: https://aisafety.stanford.edu/
IBM and AWS. (2024). "Executive Insights: Securing Generative AI Report." Available at: https://d1.awsstatic.com/onedam/marketing-channels/website/aws/en_US/whitepapers/approved/executive-insights/securing-generative-ai-report-pdf.pdf
Feffer, M., Sinha, A., Deng, W. H., Lipton, Z. C., & Heidari, H. (2024). "Red-Teaming for Generative AI: Silver Bullet or Security Theater?" arXiv preprint arXiv:2401.15897.
(ISC)2. (2024). "Cybersecurity Workforce Study." Available at: https://www.isc2.org/research
National Institute of Standards and Technology. (2023). "Artificial Intelligence Risk Management Framework (AI RMF 1.0)." NIST AI 100-1. Available at: https://www.nist.gov/itl/ai-risk-management-framework